stage4day4section5-6
Section5:Transformer
続き
実装演習
lecture_chap2_exercise_public.ipynb


訓練には10分くらいかかった
Section6:物体検知・セグメンテーション
物体検知
講義動画:物体検知とSS解説_1
【代表的データセット4つ】コンペの略称+末尾の数字は20xxの年号
・VOC12(Visual Object Classes) - クラス 20、Train + Val 11,540, Box/画像 2.4
・ILSVRC17(ImageNet Scale Visual Recognition Challenge) - Instance Annotation(物体個々へのラベリング)が与えられていない - クラス 200、Train + Val 476,668、Box/画像 1.1 - コンペは2017に終了
・MS COCO18(マイクロソフトCommon Object in Context) - クラス 80、Train + Val 123,287、Box/画像 7.3
・OICOD18(Open Images Challenge Object Detection) - クラス 500、Train + Val 1,743,042、Box/画像 7.0 - 一様な画像サイズではない
利用目的によって適切な【Box/画像】を選ぶ
・Box/画像が小さい ⇒ アイコン的な映り、日常とはかけ離れている ・Box/画像が大きい ⇒ 部分的な重なりあり、日常生活のコンテキストに近い
・クラス数とBox/画像の2軸でデータセットを分類 - 目的に応じたBox/画像を用いる - クラス数が大きければよいとは限らない > 同じものが異なるラベルになっているが故にクラス数が増えている可能性もある
例:同じノートパソコンなのに、一方はLaptop 他方はNotebook
評価指標
まずは混合行列(Confusion Matrix)を復習 TP,TN,FP,FN
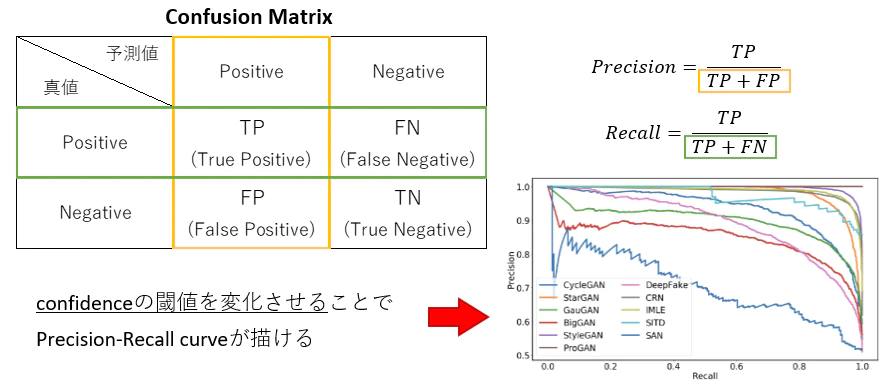
適合率 Precision = 再現率 Recall =
・クラス分類の場合 Threshold(閾値)が変わってもConfusion Matrixに入る数は変わらない
・物体検出の場合 Thresholdが変わるとConfusion Matrixに入ってくる数も変化する
上記2つの違いを認識すること!
・IoU(Intersection over Union) - クラスラベルだけでなく、物体位置の予測精度も評価したい - Jaccard係数
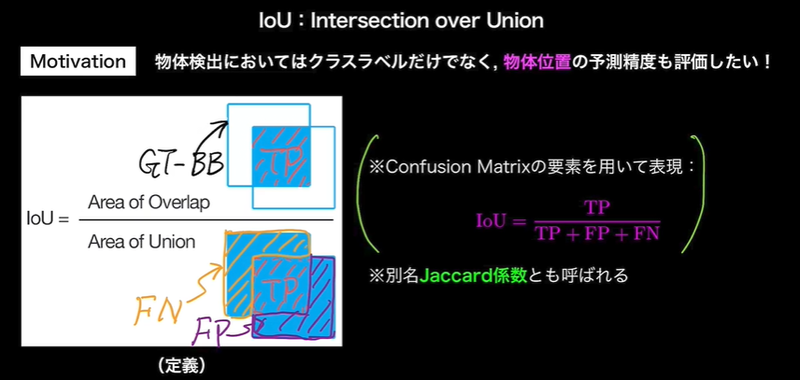
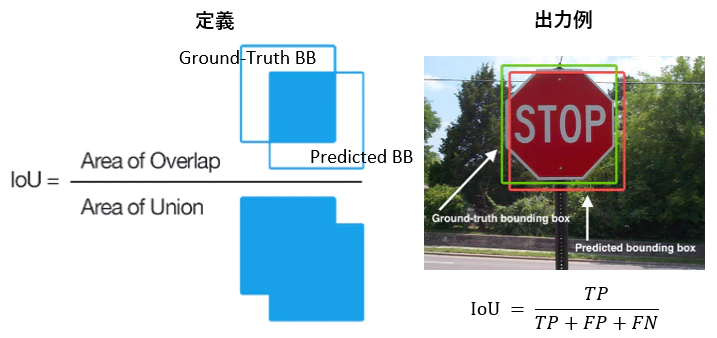
・IoUに対しても閾値を用意する
IoUに対し、反例を意識しながら考えると理解しやすい
・同じ物体に対して、複数のBBで予測してしまった場合は、最も値の高いもののみを残す
・AP(Average Precision) - Confidenceの閾値を0~1で変えて、積分する
・mAP(mean Average Precision) - 各物体に対してAPを計算し、それらの平均をとってmAPとする
・IoU閾値も0.5から0.95までの0.05刻みでAP, mAPを計算し、
算術平均を計算(MS COCOで導入された指標 mAP_COCO)
・FPS(Flames per Second) - 応用上の要請から、検出精度に加えて検出速度も問題となる
物体検知の大枠(SIFTからDCNNへ)
・2段階検出(物体位置を検出後、切り出して推論) - 候補領域の検出と暮らす推定を別々に実施する - 相対的に精度が高い - 計算量が大きく推論も遅い → リアルタイムに向かない
・1段階検出 - 同時に行う - 精度が低い - 計算量が小さく推論も速い → リアルタイムに向く
講義動画:物体検知とSS解説_2
SSD(Single Shot Detector)
1段階検出として有名
・処理の流れ 1. Default Boxを用意 2. Default Boxを変形し、Confidenceを出力
・VGG16はSSDのベース(全結合層とConvolution層で16層) - 最後の3層の全結合層の内、2層がConvolution層になっている - 最後の全結合層は削除 - マルチスケール特徴マップ
・特徴マップからの出力 - 1つのDefault Boxからの出力はクラス + 4(位置) - k個のDefault Boxからはk(クラス + 4) - 特徴マップのサイズがm x nの場合、kmn(クラス + 4)
・物理的なサイズと解像度を混同しないようにする 【初学者あるある】 - 物理的なサイズが変わるのではない。フレームサイズは同じ
特徴マップサイズが小さくなると解像度が荒くなっている
・多数のDefualt Boxによる問題 - Non-Maximum Suppression > 1つの物体のみ映っていても、複数のPredicted BBが出てしまう >> IoUが閾値以上で、Confidenceが最も大きなもののみを残す
- Hard Negative Mining > 背景ばかりになってしまう >> 背景と非背景の比を一定に保つ
・DSSDはResNetをベースにしている
セグメンテーション
講義動画:物体検知とSS解説_3
Semantic Segmentation
covolutionやpooling をかますことにより解像度が落ちていく - Semantic Segmentationでは入力画像と同じサイズの画像の各ピクセルに対して、
クラス分類が行われる > 落ちた解像度をどのようにして元の入力画像サイズまで戻すのか
・Up-sampling
covolutionやpooling で落ちる解像度を元に戻すことをUp-samplingという。
Up-samplingの壁、Up-samplingを如何に行うかが肝
初学者の無邪気な疑問 「Poolingしなければよいのでは」 - 正しく認識するためには受容野にある程度の大きさが必要 (小さい枠で、一部だけを見せられてもわからない)
> 深いConv.層 >> 多層化に伴い、計算量が増える > プーリング(ストライド)
・VGG16の全結合層3層をConv.層に変えている - ヒートマップのようなものが出力される
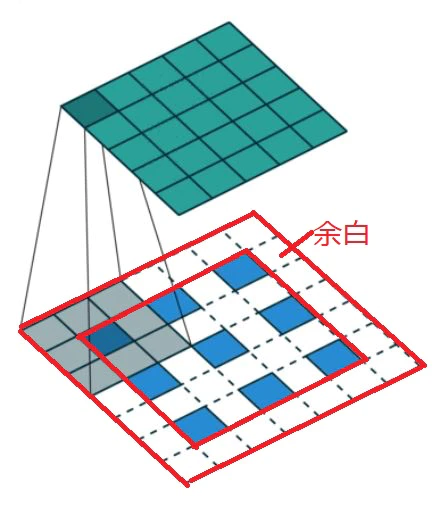
・Deconvolution/Transposed convolution - 特徴マップの間隔を空けて、パディングで余白を作ってサイズを大きくしてから、畳み込みでアップサンプリングする
- Poolingで失われた情報が復元されるわけではない
・低レイヤーのPooling層の出力をelement-wiseに足す - U-Netが代表的
・Unpooling - poolingした時の位置情報を保持しておく
戻す時は位置情報をもとにunpoolingを行う
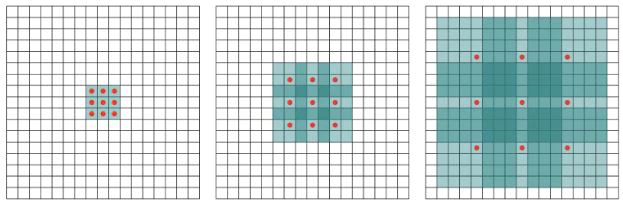
・Dilated Convolution - プーリングをするのは受容野を広げるためであるため、
代わりに畳み込みの段階で受容野を広げる工夫のこと
カーネルの各ピクせルの間を空けることで受容野を広げている